Author: ositanwanevu.bsky.social (did:plc:2ylgbet7hkz6ntdh6eljnsri)
Record🤔
cid:
"bafyreihfz6jqcggxaoxqv5yn6dll4zdnnwgxiaembtd5mvmonmotttzmvu"
value:
text:
"Is anyone going to do anything? Ever? What's it going to take? You can't put out a song with an uncleared sample without putting yourself in legal jeopardy; meanwhile these people are openly stealing all of human creation and bragging about it! www.nytimes.com/2024/04/06/t..."
$type:
"app.bsky.feed.post"
embed:
$type:
"app.bsky.embed.images"
images:
alt:
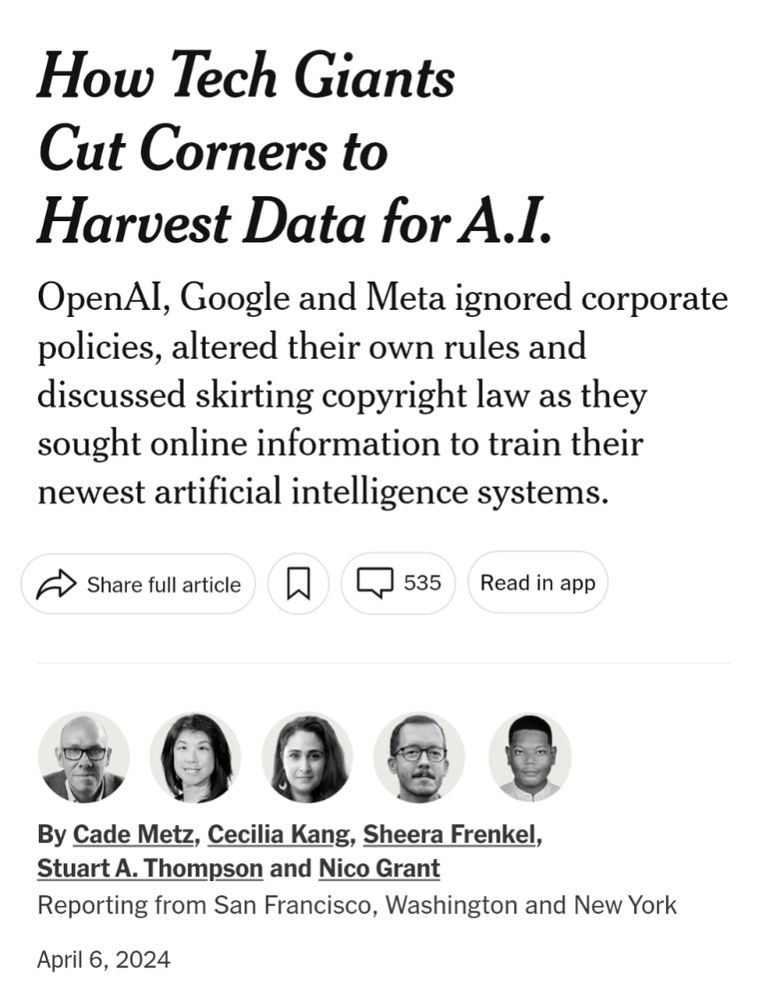
"How Tech Giants Cut Corners to Harvest Data for A.I. OpenAI, Google and Meta ignored corporate policies, altered their own rules and discussed skirting copyright law as they sought online information to train their newest artificial intelligence systems."
image:
View blob content
$type:
"blob"
ref:
$link:
"bafkreibxtnrr76pdrjwggegwzs7462fg23glc3yrnmy4y2djr37nrbgdai"
mimeType:
"image/jpeg"
size:
237785
aspectRatio:
width:
863
height:
1126
alt:
"Ahmad Al-Dahle, Meta’s vice president of generative A.I., told executives that his team had used almost every available English-language book, essay, poem and news article on the internet to develop a model, according to recordings of internal meetings, which were shared by an employee. Meta could not match ChatGPT unless it got more data, Mr. Al-Dahle told colleagues. In March and April 2023, some of the company’s business development leaders, engineers and lawyers met nearly daily to tackle the problem."
image:
View blob content
$type:
"blob"
ref:
$link:
"bafkreibprhcv44rd2xih2pp4iqaces6qwlmphqlk5ufifkzjmvzo6p56ea"
mimeType:
"image/jpeg"
size:
219225
aspectRatio:
width:
864
height:
729
alt:
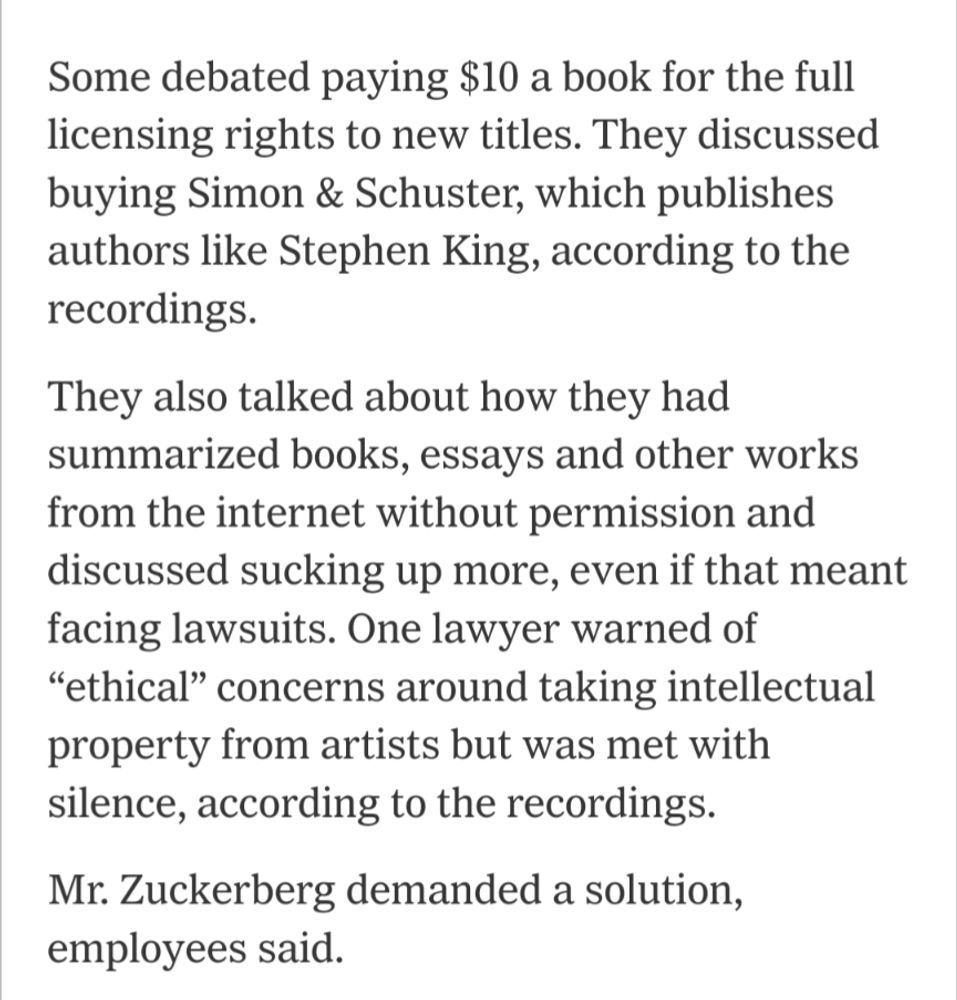
"Some debated paying $10 a book for the full licensing rights to new titles. They discussed buying Simon & Schuster, which publishes authors like Stephen King, according to the recordings. They also talked about how they had summarized books, essays and other works from the internet without permission and discussed sucking up more, even if that meant facing lawsuits. One lawyer warned of “ethical” concerns around taking intellectual property from artists but was met with silence, according to the recordings. Mr. Zuckerberg demanded a solution, employees said."
image:
View blob content
$type:
"blob"
ref:
$link:
"bafkreicc3a4tljspq7b37tn6jpo7ucqta4gmwcdj6ayvcsp52hjau7k4rq"
mimeType:
"image/jpeg"
size:
243690
aspectRatio:
width:
864
height:
903
alt:
"Meta’s executives said OpenAI seemed to have used copyrighted material without permission. It would take Meta too long to negotiate licenses with publishers, artists, musicians and the news industry, they said, according to the recordings. “The only thing that’s holding us back from being as good as ChatGPT is literally just data volume,” Nick Grudin, a vice president of global partnership and content, said in one meeting. OpenAI appeared to be taking copyrighted material and Meta could follow this “market precedent,” he added."
image:
View blob content
$type:
"blob"
ref:
$link:
"bafkreifrseugcgvrcrveztvmikneroyrnshzfha4bpstib4s5hv7wzyede"
mimeType:
"image/jpeg"
size:
229190
aspectRatio:
width:
864
height:
799
langs:
"en"
facets:
index:
byteEnd:
276
byteStart:
245
features:
uri:
"https://www.nytimes.com/2024/04/06/technology/tech-giants-harvest-data-artificial-intelligence.html"
$type:
"app.bsky.richtext.facet#link"
createdAt:
"2024-04-08T00:20:11.029Z"